🤖 Обучите YOLOv8 на пользовательском наборе данных
Статья скопирована с Хабра: https://habr.com/ru/articles/714232/
Автор оригинала: Sovit Rath

Ultralytics недавно выпустила семейство моделей обнаружения объектов YOLOv8. Эти модели превосходят предыдущие версии моделей YOLO как по скорости, так и по точности в наборе данных COCO. Но как насчет точности на пользовательских наборах данных? Чтобы ответить на этот вопрос, мы будем обучать модели YOLOv8 на пользовательском наборе данных. В частности, мы будем обучать его на крупномасштабном наборе данных для обнаружения выбоин.

Рисунок 1. Пример вывода после обучения YOLOv8 пользовательскому набору данных выбоин.
Чтобы получить лучшую модель, нам нужно провести несколько обучающих экспериментов и оценить каждый. Таким образом, мы будем обучать три разные модели YOLOv8:
- YOLOv8n (наномодель)
- YOLOv8s (маленькая модель)
- YOLOv8m (средняя модель)
После обучения мы также запустим вывод на видео, чтобы проверить реальную точность этих моделей. Это даст нам лучшее представление о лучшей модели из трех.
В дополнение к этому вы также узнаете, как использовать ClearML для ведения журнала и мониторинга обучения модели YOLOv8.
Набор данных для обнаружения выбоин для обучения YOLOv8
В этой статье мы используем довольно большой набор данных о выбоинах, который содержит более 7000 изображений, собранных из нескольких источников.
Чтобы дать краткий обзор, набор данных включает изображения из:
- Roboflow набор данных выбоин.
- Набор данных из публикации исследовательской работы.
- Изображения, полученные из видеороликов YouTube и снабженные комментариями вручную.
- Изображения из набора данных RDD2022.
После нескольких исправлений аннотаций окончательный набор данных теперь содержит:
- 6962 обучающих изображения
- 271 изображение проверки
Вот несколько изображений из набора данных вместе с аннотациями.

Рисунок 2. Аннотированные изображения из набора данных выбоин для обучения модели YOLOv8 custom
Из приведенного выше изображения очень ясно, что обучение YOLOv8 на пользовательском наборе данных выбоин является очень сложной задачей. Выбоины могут быть разных размеров, от маленьких до больших.
Загрузите набор данных
Если вы планируете выполнять обучающие команды в своей локальной системе, вы можете загрузить набор данных, выполнив следующую команду.
wget https://www.dropbox.com/s/qvglw8pqo16769f/pothole_dataset_v8.zip?dl=1 -O pothole_dataset_v8.zip
Затем распакуйте его в текущий каталог.
unzip pothole_dataset_v8.zip
Внутри каталога мы представляем набор train данных, который содержится в папках valid
и как и во всех других моделях YOLO, метки находятся в текстовых файлах с нормализованными
xmin, ymin, width, height.
Файл YAML набора данных выбоин
Для обучения нам понадобится dataset YAML для определения путей к изображениям и имен классов.
В соответствии с командами обучения, которые мы будем выполнять далее в этой статье,
этот файл YAML должен находиться в корневом каталоге проекта. Мы назовем этот файл pothole_v8.yaml.
path: pothole_dataset_v8/
train: 'train/images'
val: 'valid/images'
# class names
names:
0: 'pothole'
Согласно приведенному выше файлу, каталог pothole_dataset_v8
должен присутствовать в текущем рабочем каталоге.
Настройка YOLOv8 custom
Чтобы обучить YOLOv8 custom, нам необходимо установить ultralytics пакет.
Это обеспечивает интерфейс yolo командной строки (CLI).
Одним из больших преимуществ является то, что нам не нужно клонировать репозиторий отдельно
и устанавливать требования.
Примечание: Прежде чем перейти к дальнейшим шагам установки, пожалуйста, установите CUDA и cuDNN, если вы хотите выполнить шаги обучения в своей системе.
Мы можем установить пакет с помощью pip.
pip install ultralytics
Вышеуказанный пакет установит все зависимости, включая Torchvision и PyTorch.
Настройка ClearML
Мы не хотим вручную отслеживать наши эксперименты с глубоким обучением. Итак, мы будем использовать интеграцию ClearML, которую Ultralytics YOLOv8 поддерживает по умолчанию. Нам просто нужно установить пакет и инициализировать его с помощью API.
pip install clearml
Далее нам нужно добавить ключ API. Но перед этим нам нужно сгенерировать ключ. Следуйте инструкциям для создания и добавления ключа:
- Создайте учетную запись ClearML.
- Перейдите в Settings => Workspace область и нажмите create new credentials
Рисунок 3. Настройка ClearML.
- Скопируйте информацию в LOCAL PYTHON.
- Откройте терминал и активируйте среду, в которой установлен ClearML.
Введите и выполните
clearml-init. - Вам будет предложено вставить скопированную выше информацию. Вот и все, ваши учетные данные ClearML будут добавлены в систему.
Обучение YOLOv8 custom для обнаружения выбоин
В этом разделе мы проведем три эксперимента с использованием трех разных моделей YOLOv8. Мы будем обучать модели YOLOv8 Nano, Small и Medium на наборе данных.
Выбор гиперпараметров для обучения YOLOv8 custom
Вот несколько советов, объясняющих выбор гиперпараметров, который мы делаем во время обучения:
- Мы будем обучать каждую модель в течение 50 эпох. Для начала, как концептуальный проект, мы постараемся получить наилучшие возможные результаты при ограниченном обучении. Поскольку у нас почти 7000 изображений, даже для обучения 50 эпох потребуется довольно много времени, и они должны дать достойные результаты.
- Чтобы иметь справедливое сравнение между моделями, мы установим размер пакета равным 8 во всех экспериментах.
- Поскольку выбоины на некоторых изображениях могут быть довольно маленькими, во время обучения мы установим размер изображения с разрешением 1280. Хотя это увеличит время обучения, мы можем ожидать лучших результатов по сравнению с обучением с разрешением изображения по умолчанию 640.
Все обучающие эксперименты проводились на компьютере с 24 ГБ графического процессора RTX 3090, процессором Xeon E5-2697 и 32 ГБ оперативной памяти.
Поскольку набор данных для обнаружения выбоин довольно сложен, мы в основном сосредоточимся на карте на уровне 0.50 IoU (пересечение над объединением).
Команды для обучения YOLOv8 custom
Мы можем использовать CLI или Python API для обучения моделей YOLOv8. Прежде чем перейти к фактическому этапу обучения, давайте проверим команды и возможные аргументы, с которыми нам может понадобиться иметь дело.
Это пример обучающей команды с использованием модели Nano.
yolo task=detect mode=train model=yolov8n.pt imgsz=640 data=custom_data.yaml epochs=10 batch=8 name=yolov8n_custom
Вот пояснения ко всем аргументам командной строки, которые мы используем:
task: Хотим ли мыdetect,segmentилиclassifyна выбранном нами наборе данных.mode: Режим может быть либоtrain,valилиpredict. Поскольку мы проводим обучение, оно должно бытьtrain.model: Модель, которую мы хотим использовать. Здесь мы используем модель YOLOv8 Nano, предварительно обученную на наборе данных COCO.imgsz: Размер изображения. Разрешение по умолчанию - 640.data: Путь к файлу YAML dataset.epochs: Количество эпох, для которых мы хотим обучаться.batch: Размер пакета для загрузчика данных. Вы можете увеличить или уменьшить его в зависимости от доступности памяти вашего графического процессора.name: Имя каталога результатов дляruns/detect.
Вы также можете создать файл Python (скажем train.py)
и использовать Python API Ultralytics для обучения модели. Ниже приведен пример того же.
from ultralytics import YOLO
# Load the model.
model = YOLO('yolov8n.pt')
# Training.
results = model.train(
data='custom_data.yaml',
imgsz=640,
epochs=10,
batch=8,
name='yolov8n_custom')
В следующем разделе мы перейдем к фактическим обучающим экспериментам и при необходимости изменим аргументы командной строки.
Обучение YOLO8 Nano custom
Начиная с обучения модели YOLO8 Nano, самой маленькой в семействе YOLOv8. Эта модель имеет 3,2 миллиона параметров и может работать в режиме реального времени даже на процессоре.
Вы можете выполнить следующую команду в терминале, чтобы начать обучение. Для этого используется интерфейс командной строки Yolo.
yolo task=detect mode=train model=yolov8n.pt imgsz=1280 data=pothole_v8.yaml epochs=50 batch=8 name=yolov8n_v8_50e
Вот несколько советов относительно обучения:
- Мы обучаем модель для 50 эпох, которые останутся неизменными для всех моделей.
- Как обсуждалось ранее, мы тренируемся с 1280, который выше, чем 640 по умолчанию.
- Размер пакета равен 8.
Следующий блок кода показывает ту же настройку обучения, но с использованием Python API.
from ultralytics import YOLO
# Load the model.
model = YOLO('yolov8n.pt')
# Training.
results = model.train(
data='pothole_v8.yaml',
imgsz=1280,
epochs=50,
batch=8,
name='yolov8n_v8_50e'
)
В зависимости от оборудования, обучение займет несколько часов.
Ниже приведены окончательные графики, сохраненные в локальном каталоге после завершения всего обучения.
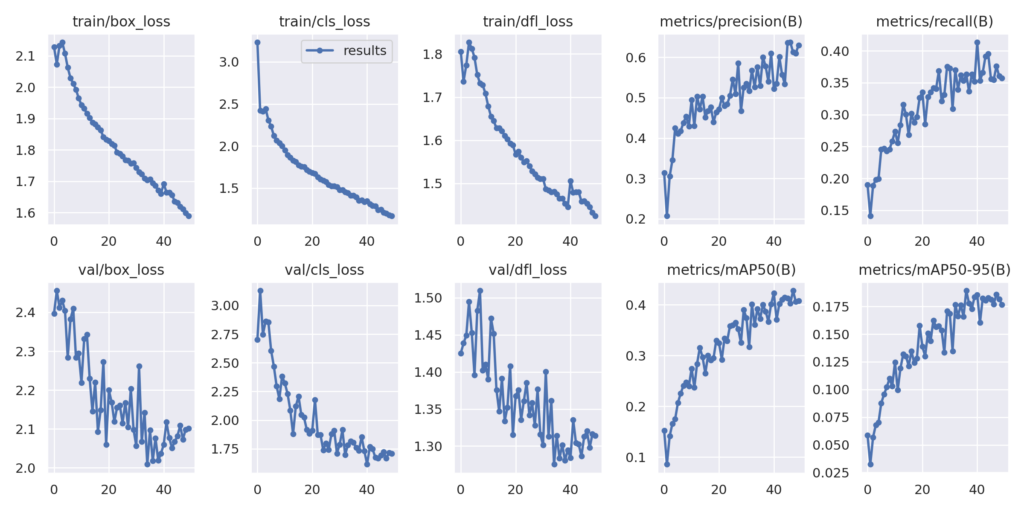
Рисунок 4. Карта и графики потерь после обучения модели YOLOv8 Nano custom
Мы также можем оценить лучшую модель, используя следующую команду.
yolo task=detect mode=val model=runs/detect/yolov8n_v8_50e/weights/best.pt name=yolov8n_eval data=pothole_v8.yaml imgsz=1280
Мы получаем следующий результат в наборе проверки.
Class Images Instances Box(P R mAP50 mAP50-95):
all 271 716 0.579 0.369 0.404 0.189
Самая высокая mAP (Mean Average Precision) at 0.50 IoU is 40.4 при 0.50:0.95 IoU is 18.9. Это может показаться меньшим, но, учитывая, что это модель Nano, это не так уж плохо.
Обучение YOLO8 Small custom
Теперь давайте обучим небольшую модель YOLOv8 small custom и проверим её точность.
yolo task=detect mode=train model=yolov8s.pt imgsz=1280 data=pothole_v8.yaml epochs=50 batch=8 name=yolov8s_v8_50e
Как и в предыдущем случае, мы также можем использовать Python API для обучения модели.
Нам нужно только изменить модель с yolov8n.pt на yolov8s.pt.
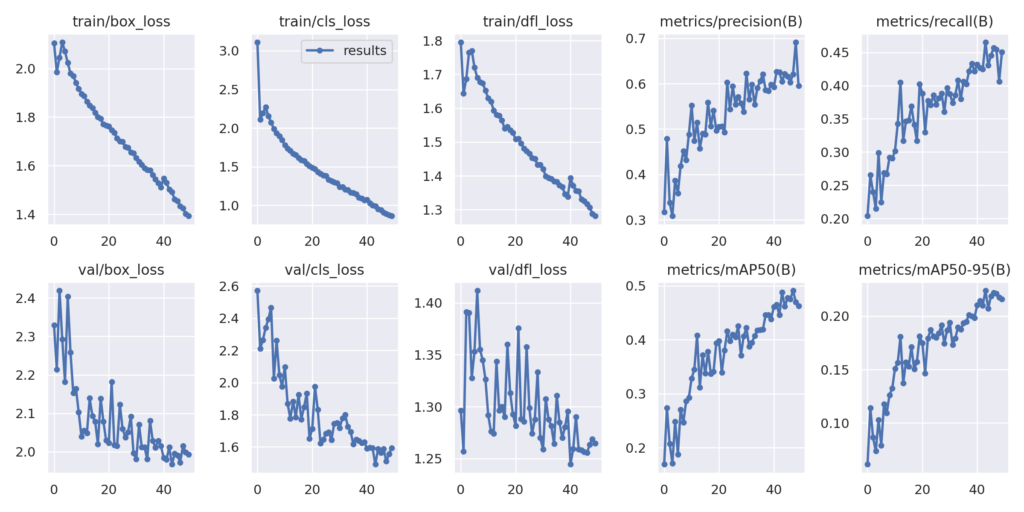
Рисунок 5. Карта и графики потерь после обучения модели YOLOv8 small custom
Используя небольшую модель YOLOv8, мы достигаем почти mAP of 50 at 0.50 IoU. Давайте запустим команду оценки, чтобы проверить фактическое значение.
yolo task=detect mode=val model=runs/detect/yolov8s_v8_50e/weights/best.pt name=yolov8s_eval data=pothole_v8.yaml imgsz=1280
Вот результаты.
Class Images Instances Box(P R mAP50 mAP50-95):
all 271 716 0.605 0.468 0.489 0.224
Модель достигает mAP 49. Это довольно хорошо для небольшой модели. В основном, размер изображения 1280 очень помогает в достижении таких цифр.
Обучение YOLO8 Medium custom
Для заключительного эксперимента мы обучим модель среды YOLOv8 на наборе данных выбоин.
yolo task=detect mode=train model=yolov8m.pt imgsz=1280 data=pothole_v8.yaml epochs=50 batch=8 name=yolov8m_v8_50e
На этот раз мы передаем модель как yolov5m.pt.
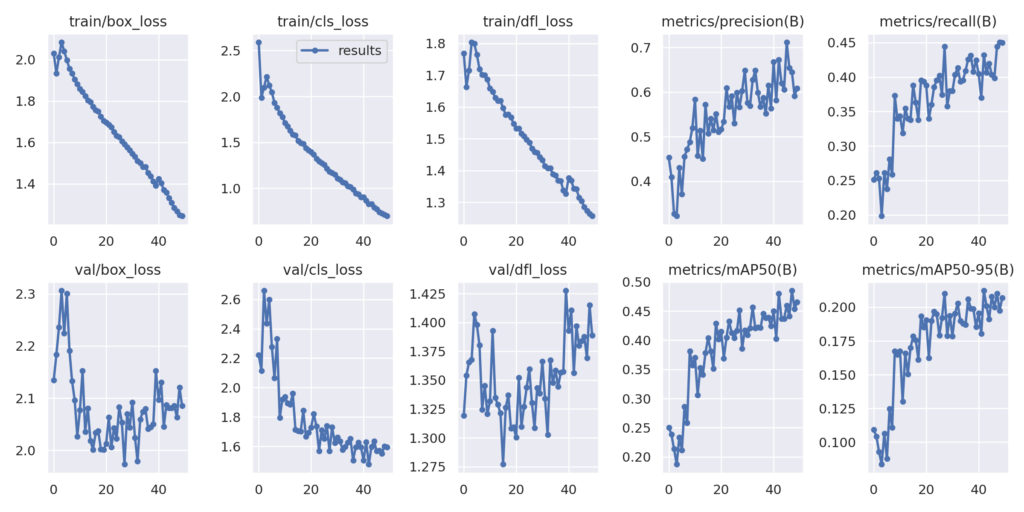
Рисунок 6. Карта и графики потерь после обучения модели YOLOv8 medium custom
Модель YOLOv8 medium также, похоже, достигает mAP почти 50. Давайте проведем оценку, чтобы получить фактические цифры.
yolo task=detect mode=val model=runs/detect/yolov8m_v8_50e/weights/best.pt name=yolov8m_eval data=pothole_v8.yaml imgsz=1280
Class Images Instances Box(P R mAP50 mAP50-95)
all 271 716 0.672 0.429 0.48 0.215
Интересно, что модель YOLOv8 Medium достигает mAP of 48 в течение 50 эпох по сравнению с mAP of 49, использующей small модель.
YOLOv8n vs YOLOv8s vs YOLOv8m
Как вы, возможно, помните, мы настроили ClearML в начале статьи. Все результаты обучения регистрировались на панели инструментов ClearML для каждого эксперимента.
Вот график из ClearML, показывающий сравнение между каждой из моделей YOLOv8 custom, обученных на наборе данных выбоин.
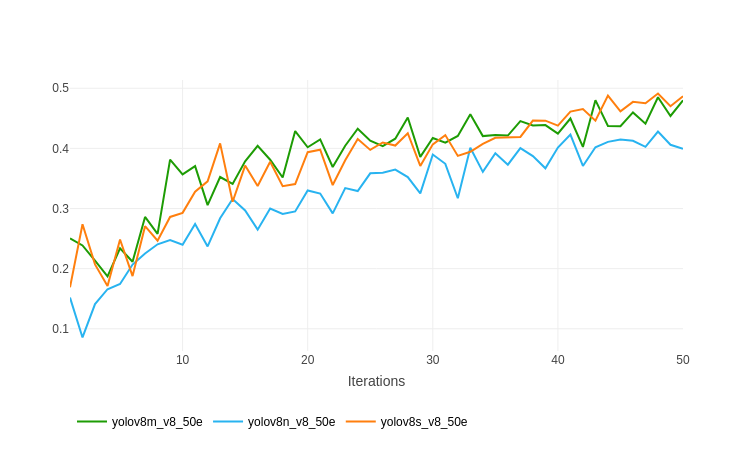
Рисунок 7. Сравнение между картой модели YOLOv8 Nano, Small и Medium при 0,50 IoU.
Приведенный выше график, показывающий карту всех трех моделей при 0,50 IoU, дает гораздо более четкую картину. Помимо модели YOLOv8 Nano, две другие модели постоянно совершенствуются в процессе обучения. И мы можем обучать эти две модели еще дольше, чтобы получить лучшие результаты.
Вывод с использованием обученных моделей YOLOv8
В настоящее время у нас есть три хорошо работающие модели. На следующем этапе экспериментов мы запустим логический вывод и сравним результаты.
Примечание: Эксперименты с выводом были выполнены на ноутбуке с 6 ГБ графического процессора GTX 1060, процессором i7 8-го поколения и 16 ГБ оперативной памяти.
Давайте запустим вывод на видео, используя обученную модель YOLOv8 Nano.
yolo task=detect mode=predict model=runs/detect/yolov8n_v8_50e/weights/best.pt source=inference_data/video_1.mp4 show=True imgsz=1280 name=yolov8n_v8_50e_infer1280 hide_labels=True
Чтобы запустить вывод, мы меняем режим на прогнозирование и указываем путь к желаемым весам модели. Источник принимает либо путь к папке, содержащей изображения и видео, либо путь к одному файлу. Вы можете указать путь к выбранному вами видеофайлу для запуска вывода.
Не забудьте указать то же imgsz, что и во время обучения, чтобы получить наилучшие результаты.
Поскольку у нас есть только один класс, мы используем hide_labels=True его,
чтобы сделать визуализации немного чище.
Клип 1. Результат YOLOv8 Nano после обучения набору данных для обнаружения выбоин.
На графическом процессоре GTX 1060 передача вперед выполнялась со скоростью почти 58 кадров в секунду, что довольно быстро при разрешении изображения 1280.
Результаты немного колеблются, а также модель способна обнаруживать выбоины только тогда, когда они находятся рядом.
Вот сравнение между всеми тремя в одном видео, чтобы получить лучшее представление о том, какая модель работает лучше всего.
Клип 2. YOLOv8 Medium против YOLOv8 Small против YOLOv8 Nano при обнаружении выбоин.
Интересно, что модель medium обнаруживает больше выбоин на больших расстояниях в первых нескольких кадрах, несмотря на то, что у нее меньше карта по сравнению с маленькой моделью YOLOv8.
Для справки, небольшая модель YOLOv8 работает со скоростью 35 кадров в секунду, а средняя модель YOLOv8 — со скоростью 14 кадров в секунду.
Вот еще одно сравнение между моделями YOLOv8 Medium и YOLOv8 Small.
Клип 3. YOLOv8 Medium против YOLOv8 Small для обнаружения выбоин. Модель YOLOv8 Medium способна обнаруживать несколько более мелких выбоин по сравнению с моделью Small.
Результаты здесь выглядят почти идентично из‑за их очень близкой карты проверки. Но в нескольких кадрах модель YOLOv8 Medium, похоже, обнаруживает небольшие выбоины.
Скорее всего, при более длительном обучении модель YOLOv8 Medium превзойдет модель YOLOv8 Small.
Резюме и заключение
В этой статье у нас было подробное пошаговое руководство по обучению моделей YOLOv8 на пользовательском наборе данных. В процессе мы также провели небольшой обучающий эксперимент в реальном мире для обнаружения выбоин.
Эксперименты показали, что обучение моделей обнаружения объектов на небольших объектах может быть сложным даже при достаточном количестве выборок. Мы могли наблюдать это, поскольку обучение в течение 50 эпох было недостаточным, а графики карт продолжали увеличиваться. Кроме того, с меньшими объектами модели обнаружения больших объектов (в данном случае YOLOv8 Medium против Nano), похоже, работают лучше при обнаружении новых изображений и видео.
Вот краткое изложение всех пунктов, которые мы рассмотрели:
- Мы начали с настройки YOLOv8 и Ultralytics.
- Затем мы увидели, как настроить ClearML для ведения журнала.
- После подготовки набора данных мы провели три разных обучающих эксперимента YOLOv8.
- Наконец, мы выполнили оценку и вывод для сравнения трех обученных моделей.
Если вы расширите этот проект, мы будем рады услышать о вашем опыте в разделе комментариев.
P.S. Код статьи на GitHub.
Extra: Q&A
Dynasaur: Запустил обучение, и пока оно идёт, возник вопрос. Если модель обучена распознавать n классов и я теперь её уче узнавать выбоины - она будет теперь знать n+1 класс? Или она забудет всё и будет уметь только выбоины? dimanosov007: Модель забывает все, и учится только для 1 или n пользовательских классов